Data Engineering Lifecycle

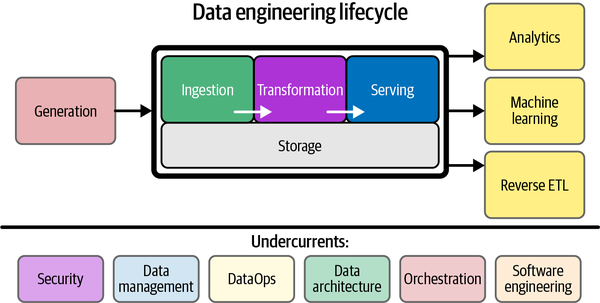
For the first publication, we will talk about the Data Engineering Lifecycle. The data engineering lifecycle may have different structures or naming conventions in other articles or publications, but the main concepts should remain the same since we are talking about the same process or goal. So, what is the purpose and place of the Data Engineer in the company?
“Data Engineering is the development, implementation, and maintenance of systems and processes that take in raw data and produce high-quality, consistent information that supports downstream use cases, such as analysis and machine learning” Fundamental of Data Engineering>
To achieve this goal, the data engineer must have a broad set of skills, for example, programming skills, usually in Python and SQL, data modeling, and have knowledge to work with different tools, such as Snowflake, BigQuery, Apache Spark and dbt. But we can talk about that in another post. However, despite these skills and technologies they need to master, technology is not the focus of a Data Engineer, but rather the use cases and the data serving. This is why understanding the data engineering lifecycle is so important, as it will make you think about where data starts is journey, where it ends and how data will flow through the pipeline, whith that you will be able to see and understand the big picture.
The Data Engineering Lifecycle 🔁
In Fundamental of Data Engineering Matt and his co-author, Joe Reis, introduced the lifecycle concept. They take the data engineering pipeline, and brake it into critical/fundamental stages that together form the data engineering lifecycle, that can turn raw data into a useful end product, ready for consumption. Despite the structure of the diagram, the separation and arrangement of the steps, the data engineering lifecycle is not always so clean and with a continuous flow, the steps may repeat themselves, occur in a different order, overlap each other, it will depend on the case.
Main Stages
Generation
Is the first stage of the lifecycle, is the origin of data. This data is created in a variety of platforms, that are external to the lifecycle, so the data engineer rarely has control over any of them. But, if it’s external why appear in the cycle, because despite of that, these platforms, databases and/or files are the generators of the data that will be used in the cycle, and data engineers must have a working understanding of how these systems operate, how they generate the data, and the frequency, velocity and variety of it.
Key elements: Understand the way source systems operate and work.
Storage
The place where the data will be stored. Storage is present in the entire data engineering lifecycle, often occurring in multiple places in the pipeline. The storage solution, and the way data is stored can impact how this data is used in all of the stages.
Key elements: Choosing the storage solution.
Ingestion
Connects to the source systems and bring the data from these systems to the pipelines. This is still raw data, but know we are in a place to clean, and transform it. We can process this data using batch ingestion or streaming ingestion (this too, will be the topic of another post).
Key elements: Understand in which way are the data being ingested.
Transformation
In this stage, data engineers start working with the data. The raw data that was ingested needs to be changed from its original form into something useful. Here is where we can change the data formats, apply business logic, and model the data. Due to that, in this stage is where data starts to get some value for the business.
Key elements: Understand and standardize the implementation of business logics; Data Modeling;
Serving
In this final stage the data – that was stored, ingested and transformed – is coherent and ready to be served to the end users, so that the data starts generating value. This data could be used, for example, in Analytics, Machine Learning, Business Intelligence.
Key elements: Ensure usability and usefulness of the data.
Undercurrents
These six concepts act as a foundation and run through various stages of the data engineering lifecycle. These concepts are valuable for each phase and should be kept in mind when going through them.
Security
As data engineers security must be a top priority, that’s why is the first undercurrent concept. At every step of the lifecycle, we must keep private or sensitive data private and protected from misuse and leaks. That’s why we must give users only the access they need to their jobs and nothing more, and only for the necessary duration to do it.
Data Management
“Is the development, execution, and supervision of plans, policies, programs, and practices that deliver, control, protect, and enhance the value of data and information assets throughout their lifecycle” DAMA - DMBOk.Is the set of best practices that data engineers will use to accomplish their tasks, technically and strategically. It is a cohesive framework that can be adopted to ensure that the organization gets value from the data and handles it properly.
DataOps
It aims to improve the release and quality of data products. Encompasses a collection of technical practices, workflows, cultural norms, and architectural patterns that will enable rapid innovation and experimentation, delivering new insights to customers with increasing velocity, higher data quality and lower error rates, and clear measurement, monitoring, and transparency of results. It is a set of cultural habits, which need to be implemented and adapted to each organization. It has three core technical elements: Automation, Observability and Monitoring, and Incident Response.
Data Architecture
Understand the bigger picture, the architecture must reflect the current and future state of the data systems, that support an organization’s long-term data needs and strategy.
Orchestration
Is the process of coordinating many jobs to run as quickly and efficiently as possible on a scheduled cadence.
Software Engineering
This always has been a central skill for data engineers. The tools are not the focus and don’t define data engineers, but they have to be proficient in them.
These are the definitions and some considerations about the main concepts of the model that I think best represents the data engineer lifecycle. As we had only a brief introduction to the concepts of each of these stages, in the next posts we will go deeper into each of them, so that we can understand them completely.
My goal in doing this is to shift the focus a bit from the tools, and focus more on the big picture, the concepts and practices behind them, so that we as data engineers can make decisions planning for the future based on the right concepts and ideas. Of course, we need to know the tools and how to work with them, but if we know what is behind and why we do what we do, the understanding of the role of the tool and its function in the lifecycle, it will make us adapt faster to new situations, tools and environments, and contribute to the growth of the department we are in.
I hope you enjoyed it, see you soon. 👋