Partitioning and Bucketing


Big data is a term that refers to the ever-increasing amounts of data being generated in today's world.
As the amount of data grows, so does the need for efficient storage and processing of this data.
Optimizations are a crucial practice that teams need to have, capable of saving valuable processing time and resources, translating into tangible savings for any organization.
In this post we'll shine a spotlight on two fundamental techniques that can significantly enhance data storage and retrieval efficiency:
- • Partitioning
- • Bucketing
When we write the data to the storage solution, we can optimize the reading process of the data by implementing one, or both of these techniques.
Base Case
We have an orders data frame (orders_df), that has 9 partitions, where we have done some data cleaning and applied transformations.
Orders_df.write.mode(“overwrite”).option(“path”, “sparkwritedemo2”).save()
When we write these orders_df to the data lake, we will end up with 9 different files on our storage solution.

Now I want to read these files and do some analysis of this data. For example, count the number of orders where the status is equal to “CLOSED”.
We create a temp view:
Orders_df.createOrReplaceTempView(‘orders’)
Spark.sql(“select count(*) from orders where order_status = ‘CLOSED’”)
The system needs to scan all the files we have, to get the ones with the closed status, in larger datasets this could be very time and resources consuming. That happens because we dumped the partitions with no logic on the Data Lake. When we write the data to our Data Lake like this, the system doesn’t know what is kept where, it knows the location of the data but not its content.
PartitionBy
Partitioning the data came to resolve this issue, allowing us to divide the data when storing it, based on a key field(s).
We can have significant performance gains if we partition the data based on some logic.
We can apply some partition by a field that we know we would use to query the data.
Continuing with the above example if we want to count the number of “CLOSED” status orders, we would partition the data by the order_status column.
Orders_df.write.mode(“overwrite”).partitionBy(“order_status”).option(“path”, “sparkwritedemo2”).save()
This will store the data on the storage solution divided by folders. Each folder represents a different status. So, the number of folders we will have will be equal to the number of different statuses.
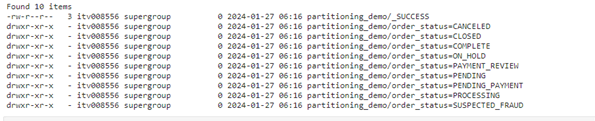
Inside each folder, we will have files that hold the data related to that status. The number of files in each folder will be equal to the number of partitions we have, in this case, since we have 9 partitions, we will have 9 files inside each folder

Now if we run the same query as before we will take advantage of the Partition Pruning.
Partition Pruning – is structuring our data so that it is stored in the underlying file systems in a way that when we filter the data it will scan only a subset of all the data.
We will only read/scan the data we want, the system will only scan the folder that corresponds to the status we want to filter for.
This will result in gains in time to process the data, and resources used to do it.
A warning is that we should not partition the data by a field that has a big cardinality, that has a large number of distinct values.
For example, 100 distinct statuses, will have created 100 distinct folders, and it would have been too much overhead for the system to deal with so much metadata.
We should only use partition when the number of distinct values is not too high for that particular column.
Bucketing
Bucketing is a way to assign rows of a dataset to specific buckets and collocate them on disk. If we want to partition the data on a field that has a high number of distinct values, we can use bucketing.
Bucketing helps in two purposes:
- • Skipping Data (dependent on the spark version used)
- • Joins
We will focus on the 1st purpose, approaching the second one in a different post related to join optimizations.
When bucketing we have to give a fixed number of buckets and the bucketing column. In this case, we will create 8 buckets, on the order_id column.
That will generate 8 files for each partition, 9*8 = 72 files in total.
In case of bucketing, we have to create a managed spark table, we cannot dump it into a folder location, the metadata of the buckets needs to be saved somewhere.
orders_df.write.mode("overwrite").bucketBy(8,'order_id').saveAsTable("itv008556_bucketing.orders_demos")
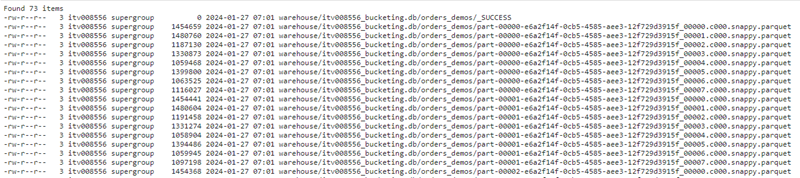
The records that go to which file are decided by a hash function.
Now if we perform a query to check for a particular order_id we will only look in the bucket files that have that order id.
| Partitioning | Bucketing |
|---|---|
| Data is physically divided into separate directories or files | Data is grouped into buckets based on a hash of the bucketing column |
| Divides data based on specified partition keys | Distributes data into predefined buckets based on a hash function |
| The field used to partition the data needs to have a low granularity | The field use to bucket the data can have a high granularity |
| Uses PARTITION BY clause in SQL or partitioning functions in DataFrame API | Uses CLUSTER BY clause in SQL or bucketBy function in DataFrame API |
| Can create an arbitrary number of partitions based on partition keys | Number of buckets is predefined and usually chosen based on the size of data and cluster configuration |
Conclusion
Optimizing data storage and retrieval processes is pivotal for enhancing the overall performance of your data pipelines. In this post, we delved into the power of partitioning and bucketing when writing data to a destination, using a practical example. These two procedures can help optimize the storage and processing of large datasets, contributing significantly to resource efficiency. By using these techniques, we can optimize the storage and processing of large datasets, making your data processing pipelines faster and more efficient.
Hope you like it. See you soon. 👋