Spark Architecture

In this post, I will talk about some knowledge and thoughts that I have collected recently about the Spark Architecture, we will be peeling back the layers to reveal the intricate framework that empowers it. Whether you're a data enthusiast or a seasoned professional, understanding Spark's inner workings is key to unlocking its full potential and harnessing the vast possibilities of big data analytics.
The Spark Cluster
At the heart of Spark's architecture lies a cluster, often comprised of several components working in harmony to process and analyze vast amounts of data.
For this architectural example, I’m using a Spark Cluster, with YARN for Resource Management, and HDFS as the storage layer.
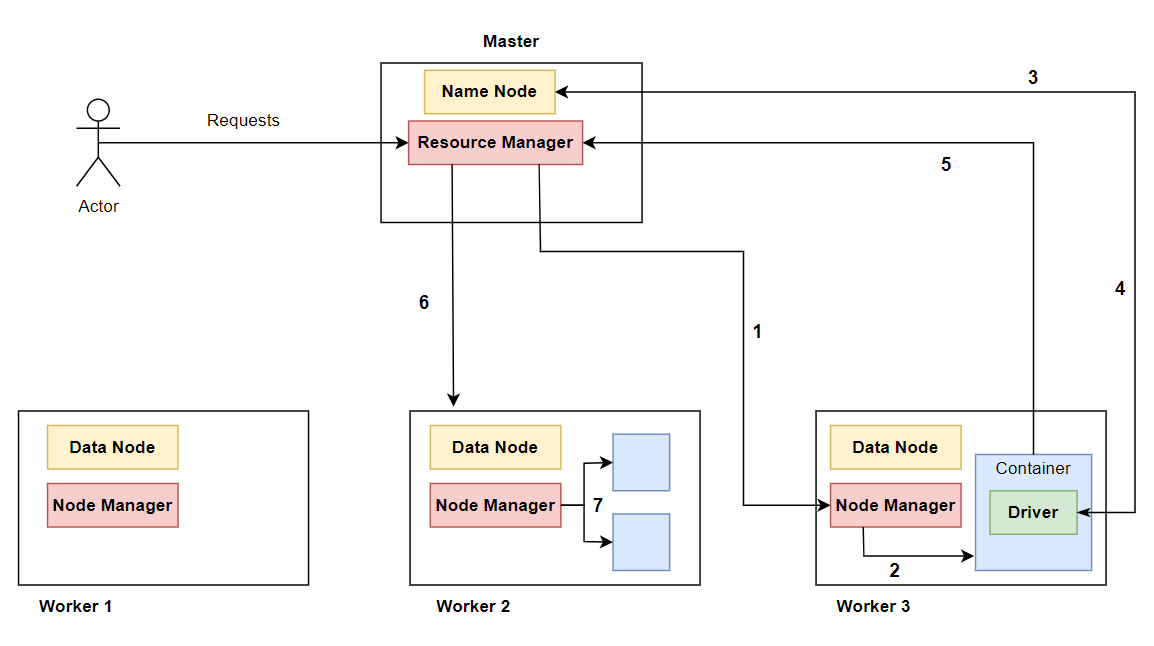
The Spark Cluster consists of one Master Node and multiple Worker Nodes. For the purpose of this example, we will assume that it is composed of 1 Master Node and 3 Worker Nodes.
In every node/machine, we have services related to Resource Management (YARN) and Storage (HDFS), on the Master, we have the Resource Manager and Name Node, and on the Worker nodes, we have the Node Manager and Data Node respectively.
The Spark Flow
When a client sends a request to the Spark Cluster, that request will be handled by the Resource Manager on the Master Node.
- 1- The request is initially handled by the Resource Manager on the Master Node. It will interact with the Node Manager of a designated Worker Node (e.g., Worker Node 3).
- 2- The Node Manager creates a container/executor. This is where the Driver service will start. The Driver acts as a local manager, , managing the application in place of the Resource Manager.
- 3- The Driver communicates with the Name Node to identify the location of the data, in which Worker Nodes the data is kept.
- 4- The Name Node informs the Driver where the data is stored.
- 5- The Driver requests resources from the Resource Manager (more containers) for specific Worker Nodes that house the partitions/blocks of data (principal of data locality).
- 6- The Resource Manager creates containers/executors (give the resources) to the Worker Nodes.
- 7- These containers are then managed by the Node Manager, allowing for the execution of the Spark job.
Modes of Operation
Spark can run in 2 different modes:
Client Mode: Client mode occurs when the driver is running on the edge/gateway node. This mode is normally used for development and testing purposes.
When we have the need to see the results immediately while we perform some transformations on the data. This is not recommended for production environments because since the driver is running on the edge node, outside the cluster, if the client machine is disconnected, shut down, or crashes the entire application will crash. (exp. when we use notebooks)
Cluster Mode: Cluster mode occurs when the driver is running as part of the cluster, in one of the worker nodes, as we see in the diagram above.
This is more suitable for a production environment, where the client packages and deploys the code, and the application runs on the backend.
The application can also run in Uber Mode:
Uber Mode: The Uber Mode occurs when we have a small-sized job to run, which can directly run on the same machine/node, using the container's resources where the Driver is kept.
By doing that the Driver will not need to request more resources from the Resource Manager, freeing resources for other applications, speeding up the execution of these small jobs.
In conclusion, understanding Spark's architecture is a pivotal step towards harnessing its immense potential in the world of big data analytics.
With an efficient cluster setup, precise resource management, and awareness of the appropriate operational mode, Spark can empower organizations to unlock insights and drive data-driven decisions.
Hope you have enjoyed it.