Inside of the Spark RDD


Spark is a general-purpose, in-memory, computing engine.
General Purpose, because it’s possible to do everything with it. Using the same code, no need to learn or know how to work with different tools.
In memory, because it processes the data in memory, using the disk in the best-case scenario only when retrieving or saving data.
Compute Engine, because it’s specialized in computation.
Spark Abstracts away the notion that we are writing the code to run across the cluster.
Is an open-source computing engine, that leverages distributed computation to process the data.
We have two layers in Spark
- • Spark Core APIs
- • Higher Level APIs
Internally both layers will work with RDDs, the code we write in the higher level will be converted to RDDs. In this post, we will be focusing on the Spark Core APIs, on the RDD level.
What are RDDs?
RDDs or Resilient Distributed Systems, are the basic units that hold the data in Apache Spark.
Resilient – because it’s resilient to failures. If we lose an RDD we can see on the DAG visualization where we lose it, and restart from there.
The RDD is immutable, which means we cannot make changes to an existing RDD, if we try to change it, we will end up creating a new one.
Spark Execution Plan
There are two kinds of operations in Apache Spark
- • Transformations
- • Actions
We have two types of transformations
Wide transformations: are transformations where the data will be shuffled.
Narrow transformations: transformations where the data will not be shuffled.
The transformations are lazy, which means that, when we write a transformation in Spark, that transformation is not executed immediately, the data is not materialized instantly on the RDD.
The transformations we perform on the different RDDs will be added to the Execution Plan, on the execution plan we will have access to the job(s), the DAG, directed acyclic graph (gives us the lineage),
and all the information about the transformations and actions performed, with detailed information on each one of them.
When an action is called on the RDD, Spark will create a job, access the execution plan, and execute the transformations and action in the best and most optimized way possible.
A job in Spark is a set of tasks that are executed in a distributed computing environment. A job is created when an action is called on an RDD (number of jobs = number of actions).
Each job is divided into stages, stages represent a set of tasks that can be executed together. A stage is created when a wide transformation is called on an RDD (number of stages = number of wide transformations + 1)
Each stage is composed of tasks, and the number of tasks is equal to the number of partitions we have.
The number of partitions is equal to the number of blocks we have divided our file into (normally 128 mb, each). However, in Spark, we have a variable that determines the default of the minimum value of partitions, which normally is equal to 2 partitions. That means if the file generates 1 block, Spark will still create two partitions with that data.
Example
Let’s imagine we want to know the count of each word in a data file, first, we will load the file, then we will apply a flat map, a map, a reduce by key, and a sort transformation, and finally, we will collect (an action) the data, to start the execution plan and retrieve the data.
Transformations and Actions
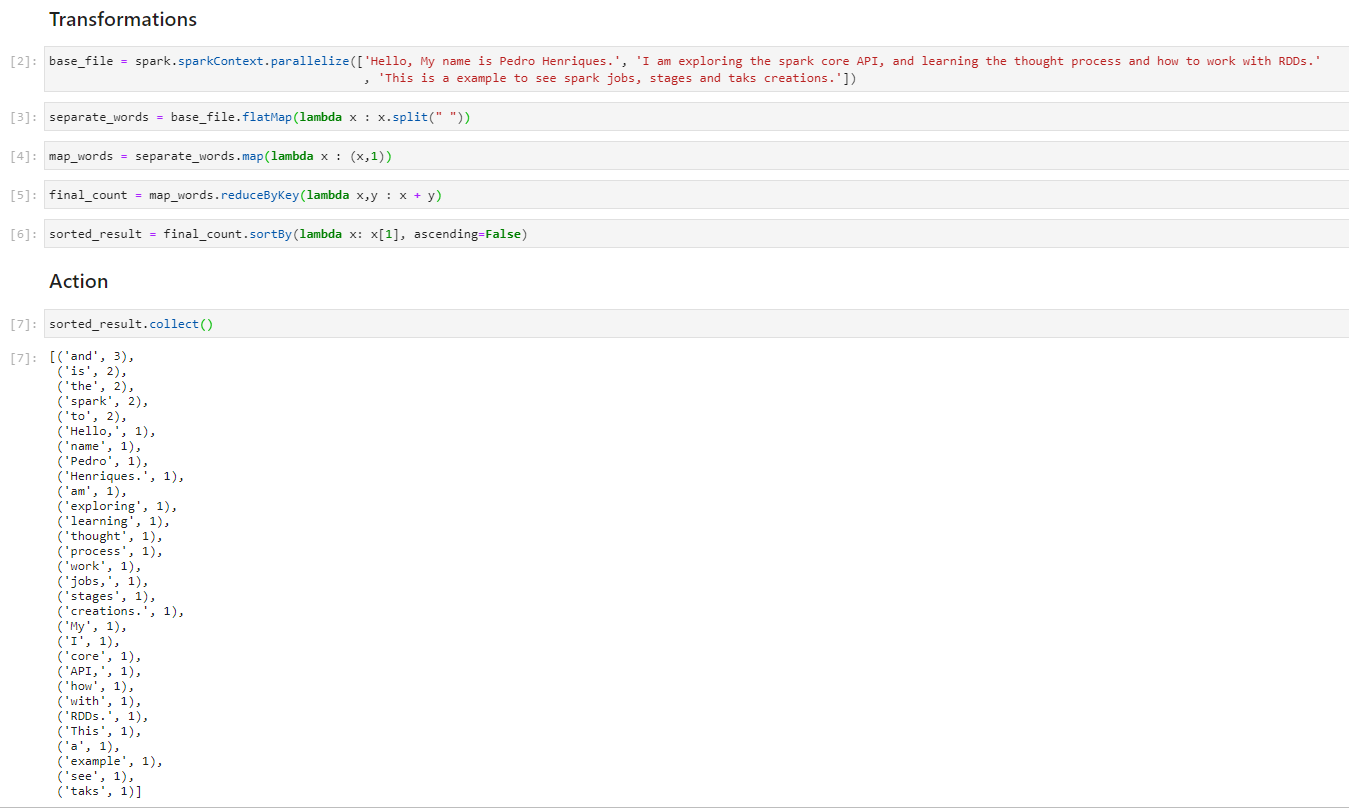
After performing the action we obtain a list with the count of the frequency of each word, sorted from the most used to the least used words.
Now lets look into the DAG that was generated for this example:
DAG Visualization
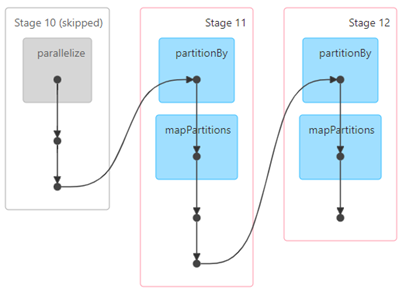
We can see we have 1 action (collect()) that creates one job.
We have 3 stages because we have two wide transformations (reduceByKey and sortBy) + 1.
We have 2 tasks in each stage, representing a total of 4 tasks on the job.
This is a small post about how the spark RDD and execution plan works, hope you have enjoyed it.