

In this project, we will build an ETL pipeline using Spotify API on AWS. The pipeline will retrieve data from Spotify API, transform it to a desired format, and load it into an AWS data store. You can access the entire code for this project on my GitHub Page - Spotify End-to-End Project
Objective
This project was developed with AWS services, to allow me to explore its products, and get familiar with it. In this project, I explore some functionalities, dependencies between services, and their connections.
With this project, I wanted to create a Data Engineer End-to-End Project, a fully automated production project, that extracts, transforms, and loads the data for analysis.
Use Case: Extract data from the artists, songs, and albums, that are present in the Global Top 50 playlist. This playlist is refreshed daily based on the streams of each track.
About the Dataset/API
For this data we retrive data from the Spotify API, about the albuns, songs, and asrtist that are present in the Global Top 50 playlist.
Services Used
- Amazon S3 (Simple Storage Service): is a highly scalable object storage service that can store and retrieve any data anywhere on the web. It is commonly used to store and distribute large media files, data backups, and static website files.
- AWS Lambda: is a serverless computing service that lets you run your code without managing servers. You can use Lambda to run code responding to events like changes in S3, DynamoDB, or other AWS services.
- Amazon CloudWatch: is a serverless computing service that lets you run your code without managing servers. You can use Lambda to run code responding to events like changes in S3, DynamoDB, or other AWS services.
- AWS Glue Crawler: is a fully managed service that automatically crawls your data sources, identifies data formats, and infers schemas to create an AWS Glue Data Catalog.
- AWS Glue Data Catalog: is a fully managed metadata repository that makes it easy to discover and manage data in AWS. You can use the Glue Data Catalog with other AWS services, such as Athena.
- Amazon Athena: is an interactive query service that makes it easy to analyze data in Amazon S3 using standard SQL. You can use Athena to analyze data in your Glue Data Catalog or in other S3 buckets.
Architecture
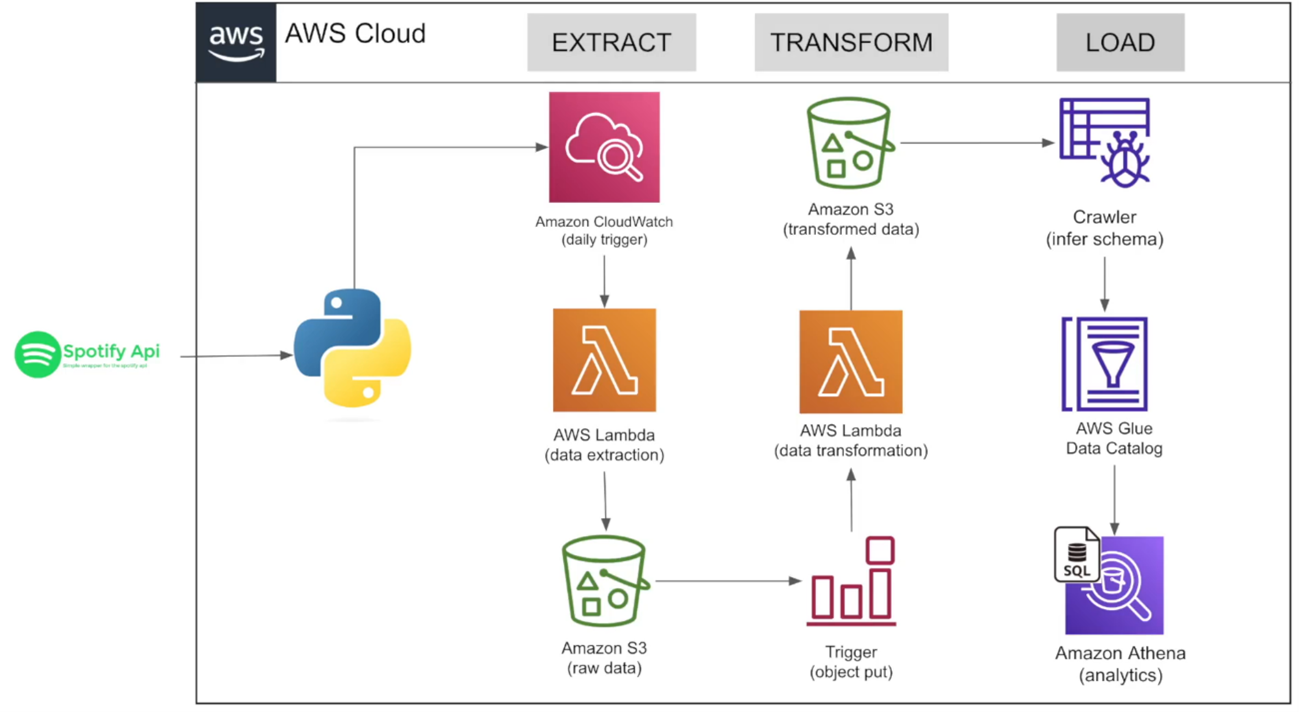
Project Execution Plan
1- Create the bucket and the respective folder structure on S3
For this structure, we create two main folders, the raw_data folder, and the transformed_data folder, to very suggestive names, that mention the data that will be stored inside of each.
Inside the raw_data folder, we will have two more folders, the to_process, which will hold the raw data that was not processed yet, and the processed folder which contains the raw extracted data that was already processed.
Inside the transformed_data folder, we have three folders, representing the three instances we are pulling the data for analyses, Artists, Songs, and Albums.
2- Extract the data from Spotify API
Create the request extract the data from the Spotify API, and store it in a raw format on the to_process folder.
In this part I worked with two different packages spotipy to connect and extract the data from Spotify and boto3 that is used to create, configure, and manage AWS services, In this particular project was used to interact with the S3 bucket created.
We create a Spotify object, that allows us to connect to Spotify and extract the data using its internal functions (playlist_tracks).
client_credentials_manager = SpotifyClientCredentials(client_id = client_id, client_secret = client_secret)
sp = spotipy.Spotify(client_credentials_manager = client_credentials_manager) # create the connected object
data = sp.playlist_tracks(playlist_URI) # pass the id of the playlist
The boto3 object, that allow us to connect to the S3 bucket and load the raw data to a specific folder.
client = boto3.client('s3')
filename = 'spotify_raw_' + str(datetime.now()) + ".json"
client.put_object(
Bucket='spotify-etl-project-ph',
Key='raw_data/to_processe/' + filename,
Body=json.dumps(data)
)
3- Transform and Load
First, we will see if exist files inside the to_process folder. If there are, we'll extract the data from each of them, one by one, and store it in a variable.
s3 = boto3.client('s3')
Bucket='spotify-etl-project-ph'
Key='raw_data/to_processe/'
for file in s3.list_objects(Bucket=Bucket, Prefix=Key)['Contents']:
file_key = file['Key']
if file_key.split('.')[-1] == "json":
response = s3.get_object(Bucket = Bucket, Key = file_key) # get the file information
content = response['Body'] # retrieve the data inside the Body
jsonObject = json.loads(content.read()) # get the actual data
Then from this data, we will retrieve the fields from the artists, songs, and albums to do further analyses.
# Geting the albums data
def album(data):
album_list = []
for row in data['items']:
album_id = row['track']['album']['id']
album_name = row['track']['album']['name']
album_release_date = row['track']['album']['release_date']
album_total_tracks = row['track']['album']['total_tracks']
album_url = row['track']['album']['external_urls']['spotify']
#creating a dictionary to store the looped data
album_elements= {'album_id': album_id, 'name': album_name, 'release_date': album_release_date,
'total_tracks': album_total_tracks, 'url': album_url}
# add that data to the list
album_list.append(album_elements)
return album_list
4- Add Triggers
The two triggers were added to the pipeline, automating the pipeline run, based on the required schedule (weekly), and on the existence of new data in the to_process folder.
EventBridge (CloudWatch Events), this first trigger is used to activate the lambda function that will extract the data from the Spotify API, on a weekly basis.
S3 this trigger is launched when there are JSON files in the to_process folder and will activate the lambda function.
Note: To complete this step we need two different permissions:
AmazonS3FullAccess - allows the connection between the lambda functions and the S3 buckets
AWSLambdaRole - allows the two lambda functions to communicate with each other.
5/6- Create Crawler and the tables on AWS Glue Data Catalog
The crawler is used to read the data from the transformed data sources and infer the schema and metadata for each of them. Creating the respective tables on the Data Catalog, based on those data sources.
7- Analyse the Data
Querying the Data using AWS Athena, using plain SQL.
Conclusion
In this project I learn some fundamental concepts when working with AWS, allowing me to explore a lot of services available on the platform.
By architecting a robust, scalable, and efficient data extraction pipeline, we have harnessed the capabilities of AWS to gather, process, and analyze Spotify data.
As we look ahead, this project serves as a testament to the endless possibilities that can be unlocked by harnessing the synergy of cloud computing and rich data sources like Spotify.
Hope you have liked it. See you soon.