Calculate the Initial Number of Partitions in Spark


Knowing the initial number of partitions is quite important for a Data Engineer, it will allow us to understand the amount of work our cluster will have, how many resources it will use, and the parallelism we can achieve.
The number of tasks on the job will be equal to the number of partitions.
Earlier when we talked about the RDD internalst, we said that the number of partitions would be equal to the number of blocks.
The default value size of blocks is 128MB. So, to calculate the number of blocks we divide the file size by 128.
We could alter the block size value, to the size we wanted, but this was the only way to calculate the number of partitions on the RDD Level.
However, on the Higher-Level APIs of Spark, we have a different way to calculate the number of partitions.
To go through this topic, we will understand some core concepts, key configurations from spark, and calculations we must perform.
We will perform the calculations for two different categories and explore a couple of scenarios:
- 1- Calculate the number of partitions for one single file.
- 2- Calculate the number of partitions for multiple small files.
Key Configurations
In every Spark Cluster, we have these three configurations:
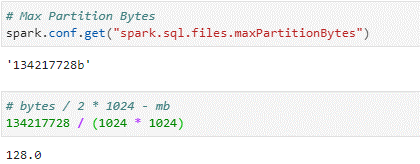
maxPartitionBytes (Spark.sql.files.maxPartitionBytes) – defines the max size of each partition, if the size of the file is bigger spark will divide it into multiple partitions.
The default number for this is 134217728 bytes = 128MB.
defaultParallelism (Spark.sparkContext.defaultParallelism) - The default value for this configuration is set to the number of all cores on all nodes in a cluster (this means the value of the existent CPU Cores of the cluster available for our job at the beginning of the process).
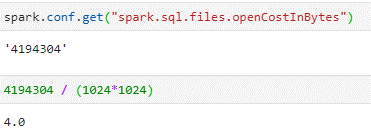
openCostInBytes (Spark.conf.get(“spark.sql.files.openCostInBytes”)) – That represents the cost it takes to open a file in bytes.
The default value is set to 4MB.
Calculating Partition Size
Partition size is a core element to calculate the number of initial partitions, if we can calculate the partition size, we will be able to determine the number of partitions.
Normally, we should not have a partition size of more than 128 MB, having a partition size greater than that could lead to slower performance, out-of-memory exceptions, and other issues on the machine related to that.
Despite 128MB being our size of reference, in some scenarios, it’s best to have a smaller size than that. This scenario happens when we have more CPU Cores available than partitions. Don’t worry if you don’t understand what I mean here, on the scenarios I will revise and explain it with examples. **
We use this method to calculate the partition size:
- Partition Size = Min(maxPartitionBytes, file size / defaultParallelism)
The calculation of the partition size will be the minimum value between the Max Partition Bytes configuration, and the total file size divided by the Default Parallelism we have at the beginning of the process.
Is based on the partition size that we will determine the number of initial partitions, so it’s important to know how Spark will calculate it so that we can understand the number of initial partitions.
1- Single File
For this first category, we will explore 2 scenarios. For both scenarios, we will read the same file and maintain the same Max partition Bytes, but we will change the Default Parallelism, and see if the number of available resources changes, the number of initial partitions will change and why.
We will use an orders file as an example for both scenarios.
Orders file size ~ 1.1GB ~ 1126MB
Max Partition Bytes = 128MB
Scenario 1
Default Parallelism = 2 CPU Cores

We have 2 executors each with 1GB of memory and 1 CPU Core.
That is a total of 2 CPU cores, so we can run a maximum of 2 tasks in parallel.
Partition Size = Min(128, 1126/2) = Min(128, 563) = 128MB
Calculating the partition size, we will divide the file size for the 2 CPU cores we have available.
The minimum value between the two will be 128MB, so the partition size is equal to 128 MB.
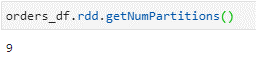
Number of Partitions = 1.1GB/128 = 9 partitions
We will have 9 initial partitions in this scenario.
Regarding the achieved parallelism, since we have only 2 CPU cores, we will have 4 rounds of 2 tasks running in parallel + 1 task.
Scenario 2 **
Default Parallelism = 16 CPU Cores
For this let’s assume we have 4 executors each with 21GB of memory and 4 CPU Cores.
This makes a total of 16 CPU Cores, so in this case we can run a maximum of 16 tasks in parallel.
Partition Size = Min(128, 1126/16) = Min(128, 71) ~ 71MB
We will divide the file size by the number of CPU cores we have available (given to us), which is 16.
The partition size now will be equal to 71MB, that happens because we augment the number of CPU cores, which means we have more power/resources, and that we can use more parallelism to compute the file. So, we can have partitions with less size.
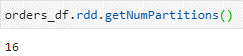
Number of Partitions = 1.1GB/71 ~ 16 partitions
Since we have 16 CPU cores, if we keep going with the 128MB partition size we would only have 9 partitions and 7 CPU cores would have been sitting idle, so to use the max resources and take advantage of all of our cluster power, we use a 71MB partition size. That will allow us to run all the tasks in parallel, and since the tasks are smaller the process will take less time to complete. So, in this way, we optimize the running process.
We will have 16 initial partitions.
Regarding the parallelism, we will have 1 round of 16 tasks running in parallel.
2- Multiple Files
When dealing with multiple files the 3 key configurations will be important.
Those 3 configurations will determine everything, the Max Partition Bytes (128MB) and the Default Parallelism (2 CPU Cores) will be used to calculate the partition size like in the previous category, the Open Cost Bytes will be an extra cost, that will be added whenever we read a single file.
We can consider the Open Cost as the time it takes to open one file, which is equal to 4 MB (i.e. the time to open the file is equal to the time it could have taken to process/read 4 MB of data).
Scenario 1
In this scenario, we will take the same orders folder from the previous category, repartition the file in 20 partitions, and write to the disk. After we will read the file from the disk, and check how the partition size and the Cost per read interfere with the number of initial partitions.
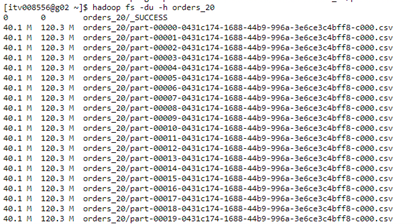
Orders file size ~ 1.1GB

We have created a folder with 20 files of 40.1MB each.
How many partitions will we have?
The default parallelism is equal to 2 CPU cores and the maximum partition bytes is equal to 128MB.
For the calculation of the partition size when we have a multiple-file folder, we use the total size of the folder we are reading and not the size of the individual file.
Partition Size = Min(128, 1126/2) = Min(128, 563) = 128MB
Based on this calculation of the size we can determine that the partition size is equal to 128MB.
So, after determining the partition size we could think that we can fit 3 files in each partition since each file is only 40.1MB
40.1 + 40.1 + 40.1 = 120.3MB
If we ignored the cost to open the files we should end up with 9 partitions, the same as in the first scenario of the One file category, since the variables are the same.
However, even though each file size is 40.1 MB, we could only join 2 files to create 1 partition. This happens because of the Open Cost, for each file we open we have a 4MB cost.
If we try to add 3 files plus the cost of the opening for each file, we end up with a bigger size than the max partition size allowed.
40.1 + 40.1 + 40.1 + 4 + 4 + 4 = 132.3MB
Each partition has 2 files, so it will create 10 partitions.
40.1 + 40.1 + 4 + 4 = 88.2MB
Number of Partitions = 10

Conclusion
In conclusion, understanding how the initial number of partitions in Apache Spark are calculated is important to know how the spark internals work, how our job will be optimized, and how much cluster resources and parallelism will we have. The determination of the initial partitions involves careful consideration of key configurations such as maxPartitionBytes, defaultParallelism, and openCostInBytes.
For a single-file scenario, we can see that Spark is smart and can dynamically adjust the partition size allowing for efficient resource utilization, minimizing idle cores, and optimizing processing time.
In the context of reading multiple files, the open cost becomes a crucial factor. Despite aiming for an ideal partition size based on file sizes, the presence of an open cost may limit the number of files that can be accommodated in a single partition.
Hope you like it. See you soon. 👋